Busigence Research
Building the art of science
We solve real complex problems through data, design & technology
We choose to work in areas through which we can directly impact thousands of souls everyday
Distributions, Comparisons, Associations, Assumptions, Randomization, Statistical Tests, Sampling, Feature Engineering
Combinatorics, Bayesian Optimization, Probabilistic Graph Models, Gradient Descent, Convex Optimization
Hyperparameter Optimization, Parameter Tuning, Meta Learning, Transfer Learning, Deep Learning, Swarm Intelligence
Ontology, Lexical Semantics, Question-Answering, Contexual, Automata Theory, Cognitive Learning, Machine Translation
Causal Analysis, Consumer Behavior, Advertising, Price Modeling, Promotion Strategy, Social Networks, Operational Systems
Algorithmic Efficiency, Concurrency Control, Fault Tolerance, Load Balancing, Data Federation,Data Resilience, Communication
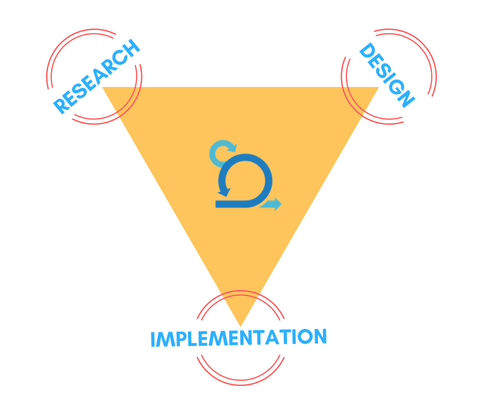
Research with a purpose
Every problem is solved on a framework build over three core pillars:
Design :: Research :: Implementation
The problem being conceived & conceptualised, is formulated by Design team.
Fomulation is validated and better formulated or at times even re-formulated by Research team. Design team takes up and shape the solution
meeting ultimate goal and objectives. Implementation team replicates the fabricated solution through best of technology stacks and achitectures
optimizing the process and making application scalable, extensible, and usable
Research is not a skill. It's a mindset
What we have been digging day & night, repeat
The subfield of optimisation, studies the problem of minimising convex functions over convex sets
Hybrid of convolutional neural networks and auto-encoder for iformation reduction from image based data to pre-process it followed by applying K-means clustering on reduced features
Speaker diarization is the task of grouping segments of speech according to the speaker. Replaced this two-step genrative process with a discriminatively trained deep neural networks(DNN) that joinly learns a fixed-dimentional embedding and scoring metric
Selecting features for designing an efficient PI detection and classification model. We note that a PI text has two major components - Prescence of consumption intent, and Prescense of corresponding consumable object
The scope of marketing research is to deliver information, which may assist or help the decider in customer decisions
Sentiment analysis of short texts such as single sentences and Twitter messages is challenging because of limited contexual information that normally contain
Apriori uses a "bottom up" approach, where frequent subset are extended one time at a time
Regression is best explained using a concept more familiar in machine learning and data mining: the bias-variance trade off
To build an uplift model, a random sample(the treatment dataset) of customer is selected to the marketing action
The purpose of muti-variate testing is to simultaneously gather information about multiple variables, and conduct analysis of the data
Detecting outliers without saying why they are outliers is not very useful in high -D due to many features (or dimentions) are involved in high dimentional data
Class imbalance is major problem in machine learning. It occurs when the number of instances in the majority class is significantly more than the numbre of instances in the minority class
That's it for now
Do you think one of the problems needs tobe solved by you? We can talk, no the other way round
Research is not an achievement. It's a requirement